DOCUMENTATION
This project was metadata oriented. Most of the work had been focused on the analysis of how to make data model more effective towards the challenges of indexing interdisciplinary and unstructured data with usability in the interaction with data.
This section describes the data structure in detail and also explain how some specific issues had been figured it along the research.
9.1. Enhanced Entity-Relationship Model (EER Model)
First thing first. The Enhanced Entity-Relationship Model (EER Model) is the high-level data model. It is very useful once it gives the macro comprehension about the data structure.
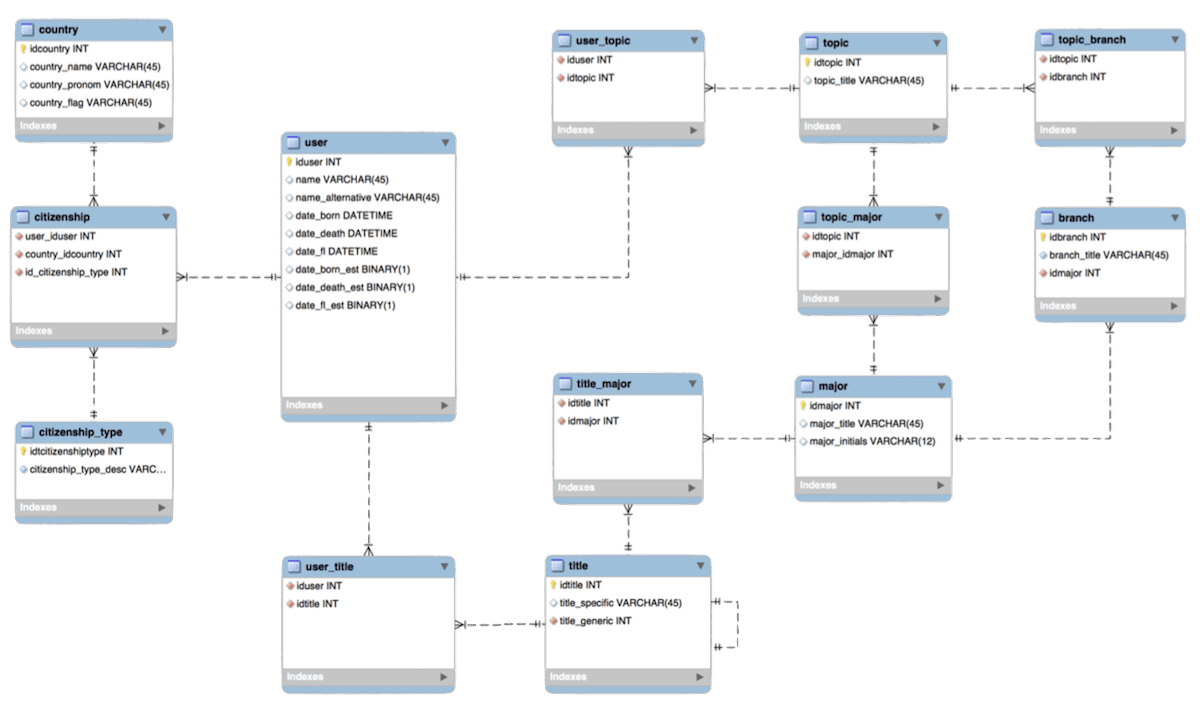
9.2. Tables
The tables on the EER model had been structured in three categories with basis on their functionalities or characteristics, as listed below: main, relationship and secondary tables.
| Title | Description |
|---|---|
| Main Tables | The main tables represent the central objects on the data model. Majors; Branches; Topics; Scientists; Titles; Countries |
| Relationship Tables | The relationship tables are responsible for creating the logical relation between the tables. Its structure depends on the kind of relationship between the objects. Citizenship; Scientist x Topic; Scientist x Title; Topic x Major; Title x Major |
| Secondary Tables | The secondary tables are used to define structured parameters used on the main and relationship tables. Citizenship type |
9.2.1.1. Majors
| Field Name | Description |
|---|---|
| id String | The unique ID of a Major |
| major_title String | Major’s Title |
| major_initials String | Major’s Acronym |
9.2.1.2. Topics
| Title | Description |
|---|---|
| id | string The unique ID of a Topic |
| title_topic | String Topic’s title |
9.2.1.3. Branches
| Title | Description |
|---|---|
| id | string Unique ID of a Branch |
| branch_title | String Branch’s Title |
| major_id | fk ($ID) The Major ID which the Branch is subordinated |
9.2.1.4. Scientists
| Title | Description |
|---|---|
| id | string The unique ID of a Scientist |
| name | String Scientist’s Name |
| name_alternative | String Alternative Scientist’s Name |
| date_birth | string($date-time) Birth date (year) |
| date_fl | string($date-time) Flourished date (year) |
| date_death | string($date-time) Death date (year) |
| date_birth_est | boolean($boolean) Define if the birth date is not precise |
| date_fl_est | boolean($boolean) Define if the flourished date is not precise |
| date_death_est | boolean($boolean) Define if the death date is not precise |
9.2.1.5. Titles
| NAME | NAME |
|---|---|
| id | String The unique ID of a Title |
| title_specific | String Title’s Description |
| title_generic | string($ID) The generic ID is an attribute that makes reference to a specific Title that will be used for structured grouped data visualization. |
9.2.1.6. Countries
For the Countries’ attributes the research adopted the World Bank standards.
| NAME | NAME |
|---|---|
| id | id string The unique ID of Country |
| country_name | String Country’s Name |
| country_full_name | String Country’s official long name |
| country_iso3 | String($integer) The three letters international code of the country |
| region | String($ID) The country region based on the current international classification |
9.3. Notes about the Data Model
The proposed data modeling have been structured addressing the main issues identified in the analyzed bibliography as well in other structured references used on the historiography of science. New versions of the data model may be available during the research period based on the contribution of scholars along the research development.
9.3.1. Multi-level Classification: Topics, Branches and Majors
The knowledge organization is based on a multi-level semantic structure labeled as Majors, Branches and Topics. The linear hierarchical relationship between them defines the main objects and creates the macro-logical of the dataset structure.
The interdependence between the objects is assigned based on the relationship tables parameters.
9.3.2. Scientists: Name and Alternative Name
Based on the bibliography analysis, the data model considers the use of two fields for the scientists’ names. The use of the alternative name is optional and it can be more detected on scientists from Middle Western countries.
9.3.3. Scientists: Birth, Death and Flourish Dates
The proposed temporality approach addressed the specific issues about the indexation of historical data instead of the usual standards for temporal modeling that consider birth and death dates.
The first issue was that the date structure adopted is composed of three data parameters: birth date, death date and flourished date (usually represented on bibliography by the use of fl with the date).
The second aspect explored was the use of attributes based on boolean parameters that define if one or more of the dates are historiographically not accurate. Thus, the date fields date_birth_est, date_death_est and date_fl_est may be enhanced with the use of the temporal attributes regarding its accuracy.
9.3.4. Citizenship
The citizenship attribute had been categorized into three types: Born, Naturalized and Contextualized. The contextual citizenship refers to the geographical contextualization for countries that have been merged and/ or changed in relation to nowadays.
For example, Persian scientists may be indexed as Persian born citizenship as well as Iranian contextual citizenship. The data model allows the coexistence of both attributes. Another example refers to the world-famous physicist Albert Einstein, who was born in Germany in 1879. Two decades later, in 1901 he obtained the Swiss citizenship thru Naturalization. Then, in 1940, Einstein also obtained North American citizenship thru Naturalization.
This approach was selected by many aspects, mostly because of the need to make the dataset available to an efficient plug-and-play integration with map API’s and other data tools. These proposed promises certainly will be discussed and validated by scholars, and contributions for this discussion will be very welcome.
It was considered initially including these fields into the user table (user), assigning specific fields for each kind of citizenship (born, naturalized and contextualized). However, after the first analysis, the data model with a separated relationship table has been demonstrated more effective for the knowledge representation on the dataset.
9.3.5. Titles
The titles are stored in two different fields on the data model: “specific title” and “generic title”. For example, a scientist that hold the specific title defined as “nuclear physicist” will also hold the generic title as “physicist”.
The use of these structured and linked fields – based on primary key ID instead of the use of syntax “anyone who has physicist” on the title – intends to create a more robust data model allowing a more sophisticated use of the data.
9.3.6. Multi-language and Multi-major Ready
The first delivery of the research project has been focused on the History of Physics, History of Chemistry and History of Mathematics. However, the data model is fully ready to operate in multi-language and multi-major.
Then, other fields of study may be incorporated in the future based on the same structure, as well it may be expanded with other historical contexts and periods.
